
The content of this work created by myself is licensed under a Creative Commons Attribution-NoDerivs 3.0 Unported License
Scripts, images and other contents not created by myself but used in this talk are released under their respective original license.
The views and opinions expressed in this talk do not necessarily represent those of my employer.



what now ?
you can achieve any two but no more of
|
|

Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services.
Nancy Lynchand Seth Gilbert. ACM SIGACT 2002
| Traditional | NoSQL MR Cloud | |
|---|---|---|
 |  | |
| Design | Vertical | Horizontal |
| Example | SAN + Rel. DB + JEE | Commodity PCs + Riak + Map-Reduce |
| Cost | 20.000 total | 70 / Unit |
| Req. Units | - | 3 |
| Reliability | 99% total | 95% / Unit |
How many commodity PCs are required to achieve equivalent reliability?

3 let random = new System.Random() 4 let systems = 5 5 let Reliability = 95 // per cent, pr = 0.95 7 let RequiredSystems = 3 9 15 [ for i = 1 to systems do yield random.Next(100) ] 16 |> List.map( fun x -> if x < Reliability then 1 else 0) 17 |> List.reduce( + )
15: generates list of random integers, range 0..99 e.g. [ 5, 56, 98, 3, 80 ]
16: maps according to reliability (0..94: running, 95..99 failure) e.g. [1, 1, 0, 1, 1 ]
17: reduces list to integer (number of running systems) , e.g. 4

|
|
|
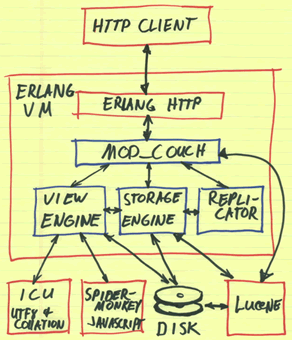
Influential
Actors in Scala, ...
Used at
Ericson, GitHub, Facebook, Twitterfall, Ubuntu, ...
in Projects/Products:
CouchDB, Riak, Membase, SimpleDB, RabbitMQ, ...
| more: |

|

|
update requires revision, i.e. proof you update the most recent version
$ curl -i -X PUT localhost:5984/test/myDoc \
-d '{"_rev":"1-967a00dff5e02add41819138abb3284d","name":"Joe"}'
HTTP/1.1 201 Created
...
Etag: "2-f800182d81918dbfc80350577842757a"
...
|
Etags for caching well defined Resources GET, PUT, DELETE (and limited use of POST) for more RESTful architecture goodness: |

|
|---|
Show Functions
map your document to different representations, e.g. HTML, JSON, ...
List Functions
represent list of (non reduced) views, e.g. index of your blog (again HTML, ATOM, JSON, ...)
 |